

Yeah ok so, bad title I know. But seriously, remember this moment above from Terminator 2: Judgement Day? https://www.youtube.com/watch?v=MT_u9Rurrqg click to the left there to watch.
Well, looks like the speech synthesis component of that instance has arrived. WaveNet - A generative model for raw audio, looks like it has massively closed the gap between computer speech synthesis and human speech. I won't attempt to summarise the whole article but, in short, far more natural sounding computer speech [and in fact almost any audio source including music] has arrived. The implications are, unnerving.
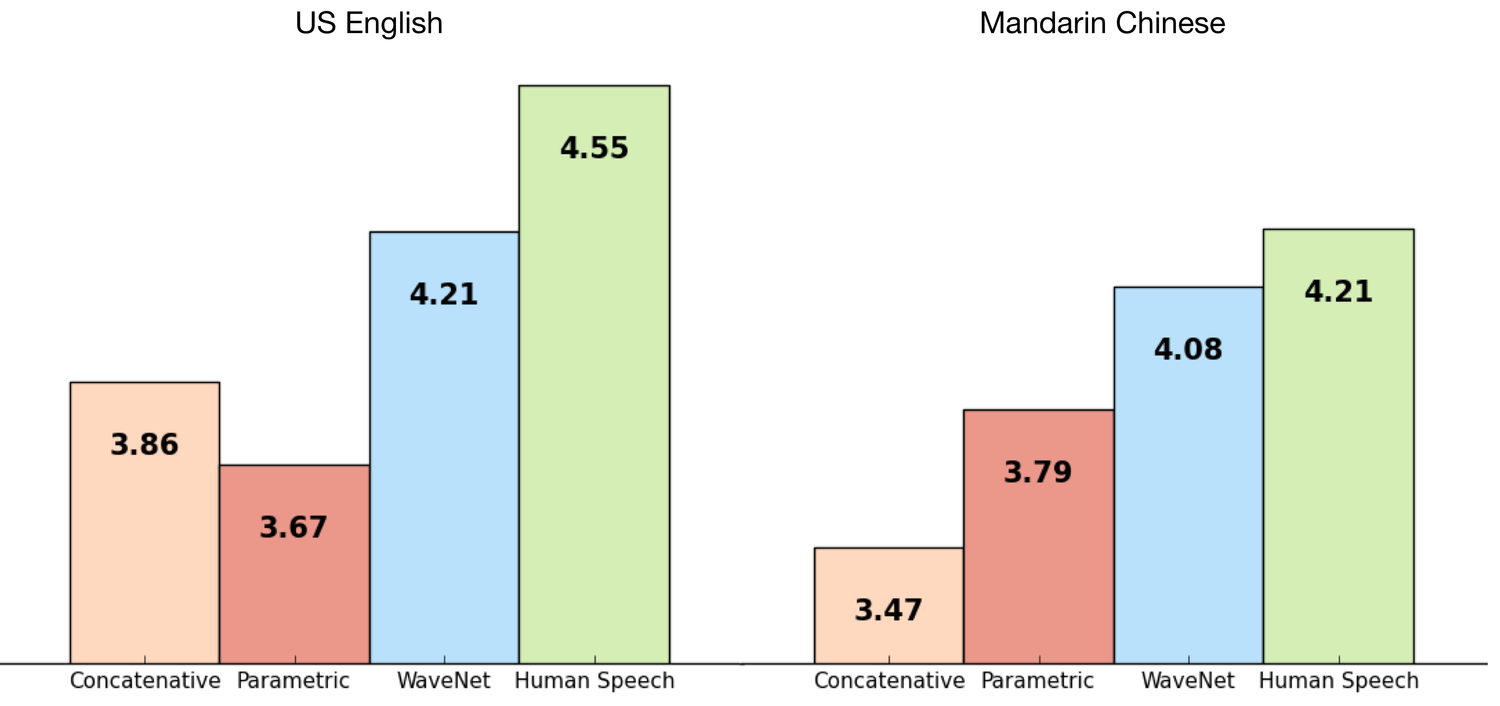
With the previous technology leader 'Concatenative' in the light pink on the far left in each graph, and human speech in green on the right, you can see where WaveNet now falls. Listen to the results yourself in the midst of the article.
This means that all the devices and smart assistants that are speaking to you and I today [Siri, Amazon Echo, Cortana, turn by turn GPS navigation etc] are not only going to sound ever more convincing, but the potential for mimicry of voice actors, politicians and people that are no longer around that we have enough samples of their speech will go through the roof.
Mimicking long dead artists' work is one facet of neural-net tech, this is another.
Incidentally, in that same article are some amazing [and frightening] piano music examples. I think the results are maybe physically impossible to play. They are interesting in a somewhat schizophrenic fashion.
-j